
My Data Tech Directory
DOWNLOAD THE TECH DIRECTORY:
Feel free to download the Markdown with all the data showed below at the directory. Enjoy!
Download the Directory
I Recently started up writing a directory table with data-related technologies. Due to my job, having a directory with all the hot data technologies I use was becoming a priority. So I wrote this table where you can sort technologies by their name, developer, license, or category and read a small summary about each technology.
Data Tech Directory
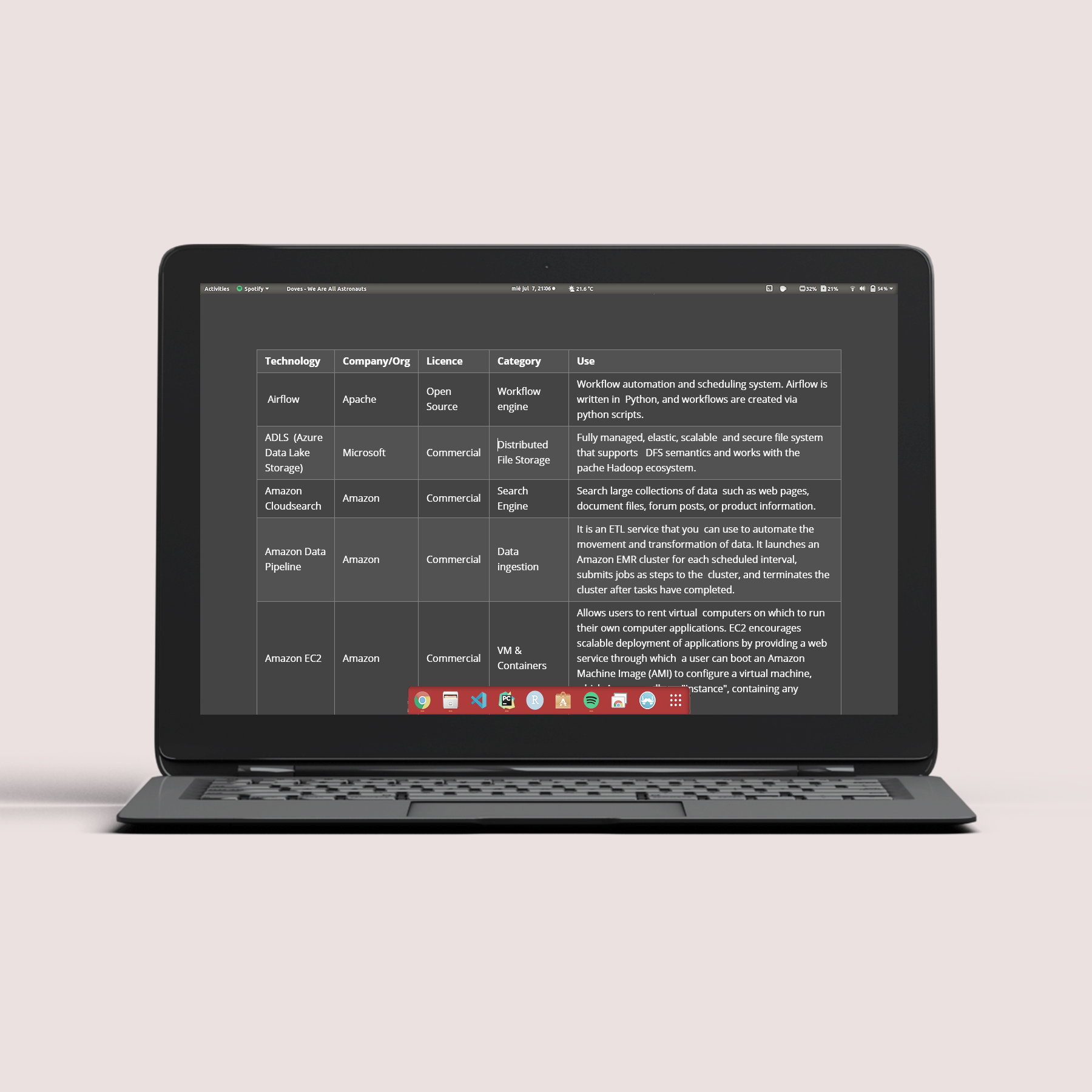
| Technology | Developer | Licence | Category | Use |
|---|---|---|---|---|
| Airflow | Apache | Open Source | Workflow engine | workflow automation and cheduling system. Airflow is written in Python, and workflows are created via python scripts. |
| ADLS (Azure Data Lake Storage) | Microsoft | Commercial | Distributed File Storage | Fully managed, elastic, scalable and secure file system that supports DFS semantics and works with the pache Hadoop ecosystem. |
| Amazon Cloudsearch | Amazon | Commercial | Search Engine | Search large collections of data such as web pages, document files, forum posts, or product information. |
| Amazon Data Pipeline | Amazon | Commercial | Data ingestion | It is an ETL service that you can use to automate the movement and transformation of data. It launches an Amazon EMR cluster for each scheduled interval, submits jobs as steps to the cluster, and terminates the cluster after tasks have completed. |
| Amazon EC2 | Amazon | Commercial | VM & Containers | Allows users to rent virtual computers on which to run their own computer applications. EC2 encourages scalable deployment of applications by providing a web service through which a user can boot an Amazon Machine Image (AMI) to configure a virtual machine, which Amazon calls an "instance", containing any software desired. |
| Amazon EMR | Amazon | Commercial | Data Processing | Amazon EMR uses Hadoop, to distribute your data and processing across a resizable cluster of Amazon EC2 instances. |
| Amazon GLUE | Amazon | Commercial | Data Processing | AWS Glue is a fully managed ETL service to categorize your data, clean it, enrich it, and move it reliably between various data stores and data streams. AWS Glue consists of a central metadata repository known as the AWS Glue Data Catalog, an ETL engine that automatically generates Python or Scala code, and a flexible scheduler. |
| Amazon Lambda | Amazon | Commercial | Data Processing | AWS Lambda was designed for use cases such as image or object uploads to Amazon S3, updates to DynamoDB tables, responding to website clicks, or reacting to sensor readings from an IoT connected device. |
| Amazon ML | Amazon | Commercial | ML & AI | A managed cluster platform that simplifies running big data frameworks, such as Apache Hadoop and Apache Spark, on AWS to process and analyze vast amounts of data. |
| Amazon Neptune | Amazon | Commercial | Data Storage | Is a managed graph Data Storage product published by Amazon.com. It is used as a web service and is part of Amazon Web Services (AWS). |
| Amazon SageMaker | Amazon | Commercial | ML & AI | A fully managed machine learning service. It provides an integrated Jupyter authoring notebook instance for easy access to your data sources for exploration and analysis, so you don't have to manage servers. |
| Ambari | Apache | Open Source | Cluster Management | Ambari enables system administrators to provision, manage and monitor a Hadoop cluster, and also to integrate Hadoop with the existing enterprise infrastructure. |
| Anaconda | Anaconda | Commercial | Frameworks | Anaconda is a distribution of the Python and R programming languages for scientific computing, that aims to simplify package management and deployment. |
| APIGee | Commercial | REST API | It was an API management and predictive analytics software provider before its merger into Google Cloud. | |
| Arrow | Apache | Open Source | Data Processing | Software framework for developing data analytics applications that process columnar data. It contains a standardized column-oriented memory format that is able to represent flat and hierarchical data for efficient analytic operations on modern CPU and GPU hardware. |
| Athena | Amazon | Commercial | Query Engine | Amazon Athena is an interactive query service to query data and analyze big data in Amazon S3 using standard SQL. Athena uses Presto, a distributed SQL engine to run queries. It also uses Apache Hive to create, drop, and alter tables and partitions. |
| Atlas | Apache | Open Source | Data Catalog | An enterprise-scale data governance and metadata framework for Hadoop. Atlas provides open metadata management and governance capabilities for organizations to build a catalog of their data assets. |
| Aurora | Apache | Open Source | Workflow engine | A Mesos framework for both long-running services and cron jobs, originally developed by Twitter starting in 2010 and open sourced in late 2013. |
| Avro | Apache | Open Source | Data Format | Avro is an open source project that provides data serialization and data exchange services for Apache Hadoop. It uses JSON for defining data types and protocols, and serializes data in a compact binary format. |
| BigML | BigML | Commercial | ML & AI | BigML is a consumable, programmable, and scalable Machine Learning platform that makes it easy to solve and automate Classification, Regression, Time Series Forecasting, Cluster Analysis, Anomaly Detection, Association Discovery, and Topic Modeling tasks. |
| BigQuery | Commercial | Query Engine | BigQuery leverages the columnar storage format and compression algorithm to store data in Colossus, optimized for reading large amounts of structured data. BigQuery presents data in tables, rows, and columns and provides full support for Data Storage transaction semantics (ACID). |
|
| Cassandra | Apache | Open Source | Data Storage | A distributed, wide-column store, NoSQL Data Storage management system designed to handle large amounts of data across many commodity servers, providing high availability with no single point of failure. |
| Chronos | Apache | Open Source | Workflow engine | A distributed cron-like system which is elastic and capable of expressing dependencies between jobs. |
| Cloudera | Cloudera | Commercial | Data Platform | Plataforma BigData para clusters On premise. Almacenamiento: sistema de archivos HDFS. Procesamiento: MapReduce, Hive, Spark... |
| Cosmos DB | Miscrosoft | Commercial | Data Storage | A fully managed NoSQL Data Storage for modern app development. Single-digit millisecond response times, and automatic and instant scalability, guarantee speed at any scale. |
| Data Factory | Microsoft | Commercial | Data Processing | It is the cloud-based ETL and data integration service that allows you to create data-driven workflows for orchestrating data movement and transforming data at scale. Using Azure Data Factory, you can create and schedule data-driven workflows (called pipelines) that can ingest data from disparate data stores. |
| Databricks | Databricks | Commercial | Data Platform | Databricks provides a unified, open platform for all your data. It empowers data scientists, data engineers, and data analysts with a simple collaborative environment to run interactive, and scheduled data analysis workloads. |
| Databricks SQL | Databricks | Commercial | Query Engine | Databricks SQL provides a simple and secure access to data, ability to create or reuse SQL queries to analyze the data that sits directly on your data lake. |
| Django | Django | Open Source | Framework | A high-level Python web full stack framework that encourages rapid development and clean, pragmatic design. Django is a collection of Python libs allowing you to quickly and efficiently create a quality Web application, and is suitable for both frontend and backend. |
| Docker | Apache | Open Source | Container Platform | A set of platform as a service (PaaS) products that use OS-level virtualization to deliver software in packages called containers. Containers are isolated from one another and bundle their own software, libraries and configuration files; they can communicate with each other through well-defined channels. |
| Docker Swarm | Apache | Open Source | Container Platform | A container orchestration tool, meaning that it allows the user to manage multiple containers deployed across multiple host machines. One of the key benefits associated with the operation of a docker swarm is the high level of availability offered for applications. |
| DocumentDB | Amazon | Commercial | Data Storage | A managed proprietary NoSQL Data Storage service that supports document data structures and has limited support for MongoDB |
| Drill | Apache | Open Source | Query Engine | Drill is an innovative distributed SQL engine designed to enable data exploration and analytics on non-relational datastores. Users can query the data using standard SQL and BI tools without having to create and manage schemas. |
| DynamoDB | Amazon | Commercial | Data Storage | A fully managed proprietary NoSQL Data Storage service that supports key–value and document data structures and is offered by Amazon. |
| Elastic Search | Apache | Open Source | Search Engine | A search engine based on the Lucene library. It provides a distributed, multitenant-capable full-text search engine with an HTTP web interface and schema-free JSON documents. |
| Event Hubs | Microsoft | Commercial | Data Processing | A big data streaming platform and event ingestion service. It can receive and process millions of events per second. Data sent to an event hub can be transformed and stored by using any real-time analytics provider or batching/storage adapters. |
| Falcon | Apache | Commercial | Data Processing | A feed processing and feed management system aimed at making it easier for end consumers to onboard their feed processing and feed management on hadoop clusters. |
| Flask | Armin Ronacher | Open Source | Framework | A micro web framework written in Python. It is classified as a microframework because it does not require particular tools or libraries. |
| Flink | Apache | Open Source | Data Processing | A unified stream-processing and batch-processing framework. The core of Apache Flink is a distributed streaming data-flow engine written in Java and Scala. Flink executes arbitrary dataflow programs in a data-parallel and pipelined manner. |
| Flume | Apache | Open Source | Data Processing | A distributed, reliable, and available software for efficiently collecting, aggregating, and moving large amounts of log data. It is used to collect log data present in log files from web servers and aggregating it into HDFS for analysis. |
| Grafana | Apache | Open Source | Data Visualization | Grafana is a multi-platform analytics and interactive visualization web application. It provides charts, graphs, and alerts for the web when connected to supported data sources. |
| GraphDB | Ontotext | Commercial | Data Storage | An online Data Storage management system with Create, Read, Update and Delete (CRUD) operations working on a graph data model. |
| Graphite | Apache | Open Source | Data Visualization | A tool that monitors and graphs numeric time-series data such as the performance of computer systems. It collects, stores, and displays time-series data in real time. |
| Hadoop Yarn | Apache | Open Source | Cluster Management | YARN sits between HDFS and the processing engines being used to run applications. It combines a central resource manager with containers, application coordinators and node-level agents that monitor processing operations in individual cluster nodes. |
| HBase | Apache | Open Source | Data Storage | HBase is a column-oriented non-relational Data Storage management system that runs on top of Hadoop Distributed File System (HDFS). HBase provides a fault-tolerant way of storing sparse data sets, which are common in many big data use cases. |
| HDFS | Apache | Open Source | Data Format | Hadoop Distributed File System is a distributed, scalable, and portable file system written in Java for the Hadoop framework. |
| HDInsight | Microsoft | Commercial | Cluster Management | Azure HDInsight is a cloud distribution of the Hadoop components from the Hortonworks Data Platform (HDP). It makes easy, fast, and cost-effective to process massive amounts of data. |
| Hive | Apache | Open Source | Query Engine | An open source data warehouse software for reading, writing and managing large data set files that are stored directly in either the Apache Hadoop Distributed File System (HDFS) or other data storage systems such as Apache Hbase or Amazon S3. |
| Hortonworks | Cloudera | Open Source | Data Platform | A security-rich, enterprise-ready, open source Apache Hadoop distribution based on a centralized architecture (YARN), with Flow Management, Stream Processing, and Management Services components. |
| Hudi | Apache | Open Source | Data Processing | A data management framework used to simplify incremental Data Processing and data pipeline development. |
| Hue | Apache | Open Source | Query Engine | Hue provides a web user interface along with the file path to browse HDFS. The most important features of Hue are Job browser, Hadoop shell, User admin permissions, Impala editor, HDFS file browser, Pig editor, Hive editor, Ozzie web interface, and Hadoop API Access. |
| Iceberg | Apache | Open Source | Data Format | Apache Iceberg is a new table format for storing large, slow-moving tabular data. It is designed to improve on the de-facto standard table layout built into Hive, Presto, and Spark. |
| Ignite | Apache | Open Source | Data Storage | A distributed in-memory Data Storage that scales horizontally across memory and disk tiers. Ignite supports ACID transactions, ANSI-99 SQL, key-value, compute, machine learning, and other data processing APIs. |
| Impala | Apache | Open Source | Query Engine | A SQL query engine for data stored in a computer cluster running Apache Hadoop. Impala brings scalable parallel Data Storage technology to Hadoop, enabling users to issue low-latency SQL queries to data stored in HDFS and Apache HBase without requiring data movement or transformation. |
| Jupyter | Jupyter | Open Source | Notebook | An interactive web tool known as a computational notebook, which researchers can use to combine software code, computational output, explanatory text and multimedia resources in a single document. |
| Kafka | Apache | Open Source | Data ingestion | Necesita un volcado periódico a sistemas tipo Hadoop o DWH. Se combina con Storm. Usa Zookeeper. |
| Kafka Streams | Apache | Open Source | Data Processing | Kafka Streams is a client library for building streaming applications, specifically applications that transform input Kafka topics into output Kafka topics stored in an Apache Kafka cluster. It combines the simplicity of writing and deploying standard Java and Scala applications on the client side. |
| Kibana | Elastic | Kibana | Data Visualization | A data visualization and exploration tool used for log and time-series analytics, application monitoring, and operational intelligence use cases. It offers powerful and easy-to-use features such as histograms, line graphs, pie charts, heat maps, and built-in geospatial support. |
| Kinesis | Amazon | Commercial | Data Processing | A managed, scalable, AWS cloud-based service that allows real-time processing of streaming large amount of data per second. It is designed for real-time applications and allows developers to take in any amount of data from several sources, scaling up and down that can be run on EC2 instances. |
| Kubernetes | Apache | Open Source | Container Platform | An open-source container orchestration platform that enables the operation of an elastic web server framework for cloud applications. Starting with a collection of Docker containers, Kubernetes can control resource allocation and traffic management for cloud applications and microservices. |
| Livy | Apache | Open Source | Rest API | A service that enables easy interaction with a Spark cluster over a REST interface. It enables easy submission of Spark jobs or snippets of Spark code, synchronous or asynchronous result retrieval, as well as Spark Context management, all via a simple REST interface or an RPC client library. |
| Lucene | Apache | Open Source | Search Engine | An inverted full-text index. This means that it takes all the documents, splits them into words, and then builds an index for each word. Since the index is an exact string-match, unordered, it can be extremely fast. |
| Machine Learning Studio | Microsoft | Commercial | ML & AI | A cloud-based service used to build, test and deploy predictive analytics solutions based on your data. Machine Learning Studio(MLS) is a drag-and-drop tool that can be used to build ML models and publish them as web services. |
| Marathon | Apache | Open Source | Container Platform | Platform as a service or container orchestration system scaling to thousands of physical servers. It is fully REST-based and allows canary-style deployments and deployment topologies. It is written in the programming language Scala. |
| MariaDB | MariaDB | Open Source | Data Storage | An open source relational Data Storage management system (DBMS) that is a compatible drop-in replacement for the widely used MySQL Data Storage technology. |
| Mesos | Apache | Open Source | Cluster Management | A cluster manager that handles workloads in a distributed environment through dynamic resource sharing and isolation. Mesos is suited for the deployment and management of applications in large-scale clustered environments. |
| Microsoft SQL Server | Microsoft | Commercial | Data Base | A relational Data Storage management system developed by Microsoft. As a Data Storage server, it is a software product with the primary function of storing and retrieving data as requested by other software applications. |
| MongoDB | MongoDB | Open Source | Data Storage | A document-oriented Data Storage which stores data in JSON-like documents with dynamic schema. It means you can store your records without worrying about the data structure such as the number of fields or types of fields to store values. MongoDB documents are similar to JSON objects. |
| MySQL | Oracle | Open Source | Data Storage | A relational Data Storage management system based on SQL. The application is used for a wide range of purposes, including data warehousing, e-commerce, and logging applications. The most common use for mySQL however, is for the purpose of a web Data Storage. |
| Neo4j | Neo Technology | Commercial | Data Storage | A graph Data Storage management system developed by Neo4j, Inc. Described by its developers as an ACID-compliant transactional Data Storage with native graph storage and processing. |
| NiFi | Apache | Open Source | Data ingestion | An open source software for automating and managing the data flow between systems. It is a powerful and reliable system to process and distribute data. It provides web-based User Interface to create, monitor, and control data flows. |
| NuoDB | Nimbus DB | Commercial | Data Storage | A distributed relational Data Storage management system. Unlike traditional shared-disk or shared-nothing architectures, NuoDB uses a peer-to-peer messaging protocol to route queries to nodes. NuoDB splits its architecture into two layers: a transactional tier and a storage tier. |
| Nutch | Apache | Open Source | Search Engine | A web crawler software product that can be used to aggregate data from the web. It is used in conjunction with other Apache tools, such as Hadoop, for data analysis. Nutch provides extensible interfaces such as Parse, Index and ScoringFilter's for custom implementations. |
| Oozie | Apache | Open Source | Workflow jobs | A workflow scheduler system to manage Apache Hadoop jobs. Oozie Workflow jobs are Directed Acyclical Graphs (DAGs) of actions. |
| Openshift | Apache | Open Source | Container Platform | A Kubernetes distribution that helps you to develop, deploy, and manage container-based applications. It provides you with a self-service platform to create, modify, and deploy applications on demand, thus enabling faster development and release life cycles. |
| Oracle Data Storage | Oracle | Commercial | Data Storage | A multi-model relational Data Storage management system, mainly designed for enterprise grid computing and data warehousing. |
| Oracle NoSQL | Oracle | Commercial | Data Storage | A NoSQL-type distributed key-value Data Storage from Oracle Corporation. It provides transactional semantics for data manipulation, horizontal scalability, and simple administration and monitoring. |
| ORC | Apache | Open Source | Data Format | A column-oriented data storage format of the Apache Hadoop ecosystem. It provides a highly efficient way to store Hive data and was designed to overcome limitations of the other Hive file formats. Using ORC files improves performance when Hive is reading, writing, and processing data. |
| Parquet | Apache | Open Source | Data Format | A column-oriented data storage format of the Apache Hadoop ecosystem. Reads and querying are much more efficient than writing. Better optimized for Apache Spark. |
| Podman | RedHat | Open Source | Container Platform | A daemonless, Linux native tool designed to make it easy to find, run, build, share and deploy applications using Open Containers Initiative (OCI) Containers and Container Images. Podman provides a command line interface (CLI) familiar to anyone who has used the Docker Container Engine. |
| PostgreSQL | PostgreSQL | Open Source | Data Storage | An advanced, enterprise-class, and open-source relational Data Storage system. PostgreSQL supports both SQL (relational) and JSON (non-relational) querying. PostgreSQL is used as a primary Data Storage for many web applications as well as mobile and analytics applications. |
| PowerBI | Microsoft | Commercial | Data Visualization | A suite of business intelligence (BI), reporting, and data visualization products and services for individuals and teams. Power BI stands out with streamlined publication and distribution capabilities, as well as integration with other Microsoft products and services. |
| Presto | Apache | Open Source | Query Engine | A distributed SQL query engine that is used best for running interactive analytic workloads in your big data environment. Presto allows you to query against many different data sources whether its HDFS, MySQL, Cassandra, or Hive. |
| Purview | Microsoft | Open Source | Data Governance | A unified data governance service that helps you manage and govern your on-premises, multicloud, and software-as-a-service (SaaS) data. Easily create a holistic, up-to-date map of your data landscape with automated data discovery, sensitive data classification, and end-to-end data lineage. |
| Pycharm | jetbrains | Commercial | IDE | A dedicated Python Integrated Development Environment (IDE) providing a wide range of essential tools for Python developers, tightly integrated to create a convenient environment for productive Python, web, and data science development. |
| Qlik Sense | Qlik Tech | Commercial | Data Visualization | A self-service analytical tool based on the same in-memory technology as QlikView. It's associative engine allows for snappy selections, filtering and prompt re-calculation of all charts and aggregations on the fly. |
| Qlik View | Qlik Tech | Commercial | Data Visualization | A traditional, technical tool for shared business intelligence, data analytics and reporting. |
| Rabbit MQ | Pivotal | Open Source | Message Broker | A messaging broker - an intermediary for messaging. It gives your applications a common platform to send and receive messages, and your messages a safe place to live until received. It is also used between microservices, where it serves as a means of communicating between applications. |
| Ranger | Apache | Open Source | Data Governance | A framework to enable, monitor and manage comprehensive data security across the Hadoop platform. The vision with Ranger is to provide comprehensive security across the Apache Hadoop ecosystem. With the advent of Apache YARN, the Hadoop platform can now support a true data lake architecture. |
| Redshift | Amazon | Commercial | Data Processing | A managed service provided by Amazon. Raw data flows into Redshift (ETL), where it’s converted and transformed at a regular cadence, or on an ad hoc basis. It is designed to crunch large amounts of data as a data warehouse. |
| Rekognition | Amazon | Commercial | Data Processing | A cloud-based software as a service (SaaS) computer vision platform, that automatically extracts metadata from your image and video files, capturing objects, faces, text and more. This metadata can be used to easily search your images and videos with keywords, or to find the right assets for content syndication. |
| Rstudio | Rstudio | Open Source | IDE | An Integrated Development Environment (IDE) for R, a programming language for statistical computing and graphics. |
| S3 | Amazon | Commercial | Data Storage | A cloud IaaS (infrastructure as a service) solution from AWS for object storage via a convenient web-based interface. The basic storage unit of S3 is the "object", which consists of a file with an associated ID number and metadata. These objects are stored in buckets, which function similarly to folders or directories. S3 scales vertically and automatically according to your current data usage, without any need for action on your part. |
| SageMaker | Amazon | Commercial | ML & AI | A fully-managed service that enables data scientists and developers to quickly and easily build, train, and deploy machine learning models at any scale. Amazon SageMaker includes modules that can be used together or independently to build, train, and deploy your machine learning models. |
| Snowflake | Snowflake | Commercial | Data Storage | A data warehouse built on top of the Amazon Web Services or Microsoft Azure cloud infrastructure. Its architecture allows storage and compute to scale independently, so customers can use and pay for storage and computation separately. And the sharing functionality makes it easy for organizations to quickly share governed and secure data in real time. |
| SolR | Apache | Open Source | Search Engine | Solr performs text analysis on certain content and search queries in order to determine similar words, understand and match synonyms, remove syncategorematic words, and score each result based on how well it matches the query. It is built on top of lucene to provide a search platform. SOLR is a wrapper over Lucene index. |
| Spark | Apache | Open Source | Data Processing | An open-source, distributed processing engine used for big data workloads and compatible with Hadoop data. It can run in Hadoop clusters through YARN or Spark's standalone mode, and it can process data in HDFS, HBase, Cassandra, Hive, and any Hadoop InputFormat. |
| Spark SQL | Apache | Open Source | Query Engine | A Spark module for structured data processing. It provides a programming abstraction called DataFrames and can also act as a distributed SQL query engine. It enables unmodified Hadoop Hive queries to run up to 100x faster on existing deployments and data. |
| Spark Streaming | Apache | Open Source | Data Processing | An extension of the core Spark API that allows to process real-time data from various sources including Kafka, Flume, and Amazon Kinesis. This processed data can be pushed out to file systems, databases, and live dashboards. It provides us the DStream API which is powered by Spark RDDs. |
| Spark Structured Streaming | Apache | Open Source | Data Processing | This model of streaming is based on Dataframe and Dataset APIs. Hence with this library, we can easily apply any SQL query (using DataFrame API) or scala operations (using DataSet API) on streaming data. In Structured streaming, there is no concept of a batch. The received data in a trigger is appended to the continuously flowing data stream. |
| Spyder | Anaconda | Commercial | IDE | An open-source cross-platform IDE that is included with Anaconda. The Python Spyder IDE is written completely in Python. |
| Sqoop | Apache | Open Source | Data ingestion | A tool designed for efficiently transferring bulk data between Apache Hadoop and external datastores such as relational databases, enterprise data warehouses. Sqoop is used to import data from external datastores into Hadoop Distributed File System or related Hadoop eco-systems like Hive and HBase. |
| Stinger | Stinger | Open Source | Data Processing | A package designed to support streaming graph analytics by using in-memory parallel computation to accelerate the computation. STINGER is composed of the core data structure and the STINGER server, algorithms, and an RPC server that can be used to run queries and serve visualizations. |
| Storm | Apache | Open Source | Data Processing | A free and open source distributed realtime computation system. Apache Storm makes it easy to reliably process unbounded streams of data, doing for realtime processing what Hadoop did for batch processing. Storm runs on YARN and integrates perfectly with the Hadoop ecosystem. |
| Synapse Analytics | Microsoft | Commercial | Data Platform | A cloud-based enterprise data warehouse that leverages massively parallel processing (MPP) to quickly run complex queries across petabytes of data. Use Azure as a key component of a big data solution. |
| Tableu | Salesforce | Commercial | Data Visualization | A powerful and fastest growing data visualization tool used in the Business Intelligence Industry. It helps in simplifying raw data in a very easily understandable format. |
| Talend Data Platform | Talend | Commercial | Data Processing | A data integration solution helps companies deal with growing system complexities by addressing both ETL for analytics and ETL for operational integration needs and offering industrialization features and extended monitoring capabilities. |
| Thrift | Apache | Open Source | Framework | An interface definition language and binary communication protocol used for defining and creating services for numerous programming languages. It forms a remote procedure call (RPC) framework and was developed at Facebook for "scalable cross-language services development". |
| Watson Studio | IBM | Commercial | Data Platform | A platform to build, run and manage AI models, and optimize decisions anywhere on IBM Cloud Pak® for Data. Unite teams, automate AI lifecycles and speed time to value on an open multicloud architecture. |
| Zeppelin | Apache | Open Source | Notebook | Web-based notebook that enables data-driven, interactive data analytics and collaborative documents with SQL, Scala and more. |
| ZooKeeper | Apache | Open Source | Cluster Management | An open source Apache project that provides a centralized service for providing configuration information, naming, synchronization and group services over large clusters in distributed systems. The goal is to make these systems easier to manage with improved, more reliable propagation of changes. |
Other references and links
- More articles like this here: Resources